
Stop your AI agent from duplicating your codebase.
Drift measures what your linter cannot: cross-file structural coherence — the layer where pattern fragmentation, boundary violations, and duplicate divergence accumulate across commits.
77–95 % real-world precision · ~30 s for a 2 900-file codebase · 24 signals · deterministic, no LLM
pip install drift-analyzer
drift analyze # auto-detects the right profile on first run (no config needed)
drift init --auto # lock in the auto-detected config (no prompts, CI-friendly)
drift status # traffic-light health check — your daily entry point
drift status→ repo-level score (0–1 · 🟢/🟡/🔴) ·drift analyze→ per-finding detail (INFO/LOW/MEDIUM/HIGH). Baredriftrunsdrift status.
![]()






Docs · Quick Start · Playground · Benchmarking · Trust & Limitations · Community
Using AI coding tools? Start here · CI & team rollout? Team rollout guide · Benchmarks & evidence? Study
uvx drift-analyzer analyze --repo .One command. No pre-install. Results in ~30 seconds. No config needed —
drift analyzeauto-detects the right profile.drift init --autosaves it todrift.yamlwithout prompts (vibe-coding/default/strict).
🌐 No install at all? Analyze any public repo in your browser → · Interactive code playground →
Recommended install: pipx install drift-analyzer (isolated CLI) · Python 3.11+ · also via pip, Homebrew, Docker, GitHub Action, pre-commit → · best fit for Python repos with 20+ files; TypeScript/TSX: pip install 'drift-analyzer[typescript]'
Note
Drift eats its own dog food. Every release runs drift self on its own source — score 0.63 → drift_self.json. Precision/Recall details in Trust & Limitations.
Most linters catch single-file style issues. Drift catches what they miss: cross-file structural drift that accumulates silently — in any codebase, at any scale.
| Without Drift | With Drift |
|---|---|
|
|
🔍 Before —
drift briefanalyses your repo scope and generates structural constraints ready to paste into your agent prompt 🚦 After —drift checkruns 20+ cross-file signals and exits 1 on violations — CI, SARIF, and pre-commit ready 🧠 Over time — Adaptive calibration reweights signals via feedback, git outcome correlation, and GitHub label correlation 📚 Negative context library —drift_nudgedelivers structured anti-patterns (canonical alternatives + CWE tags) directly into your agent's context — no manual guardrail writing needed
| Audience | Starting point | You'll use |
|---|---|---|
| Developers using AI tools (Copilot, Cursor, Claude) | drift setup → drift status |
brief, nudge, check — catch what your agent breaks |
| Tech leads & teams adopting AI at scale | Team Rollout Guide | CI gate, SARIF, trend — enforce structural standards |
| Solo developers wanting structural quality | drift analyze --repo . |
fix-plan, explain — find and fix erosion patterns |
One page, three milestones — enough to go from first run to measurable improvement.
| Week | Goal | Commands | Done when |
|---|---|---|---|
| 1 — Baseline | See your starting point | drift setup → drift analyze --repo . --format json > baseline.json |
You have a score and a saved baseline file |
| 2 — Understand | Triage the top 5 findings | drift status · drift explain <signal> |
Each finding is marked fix, ignore, or defer |
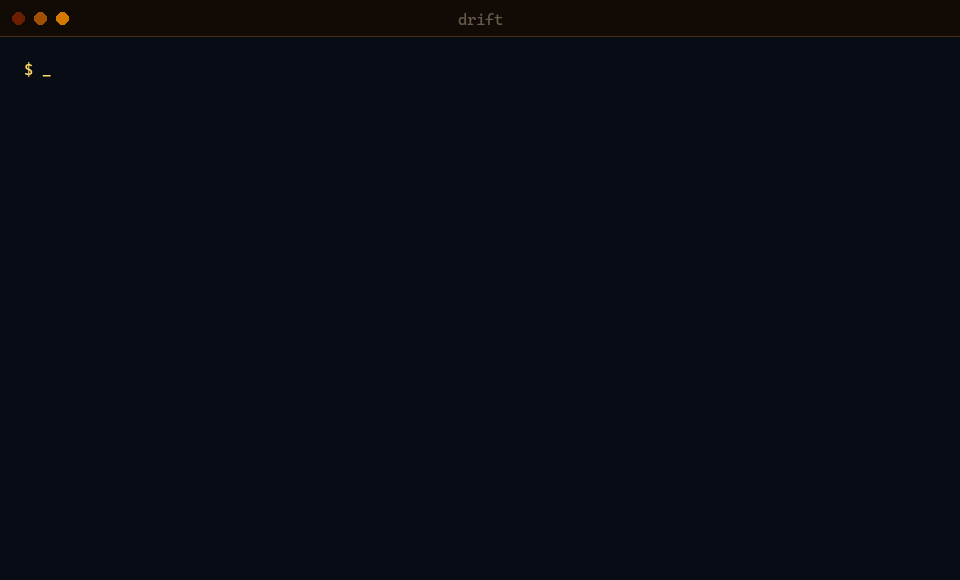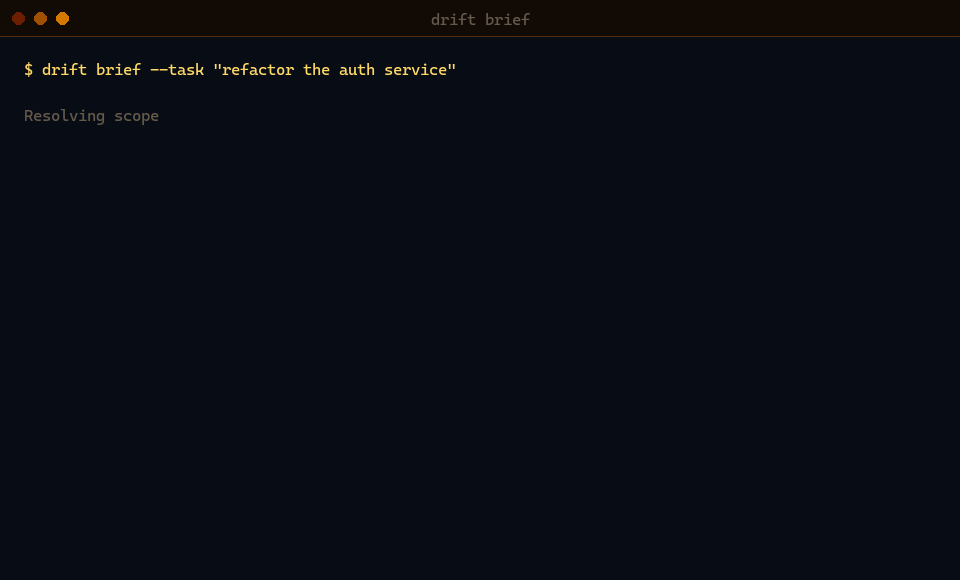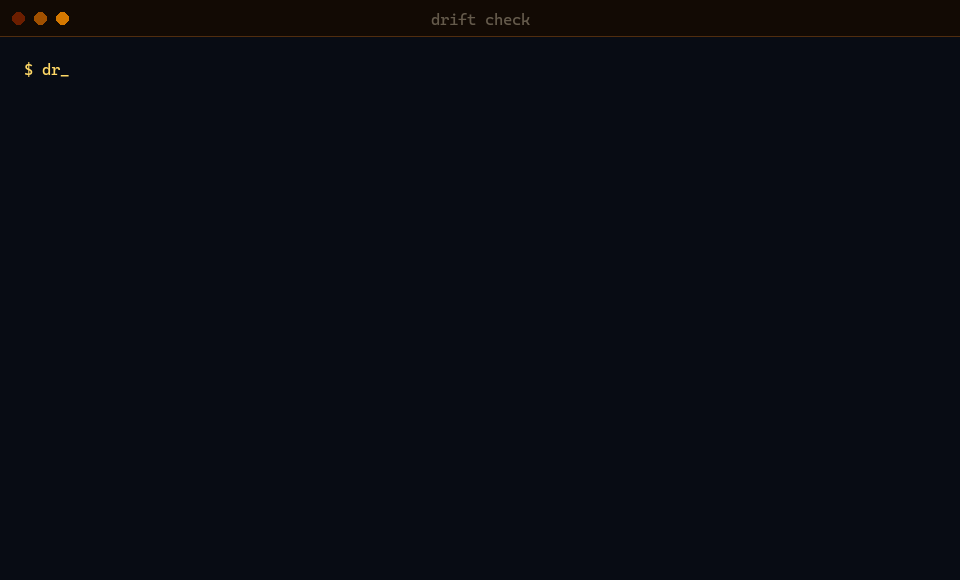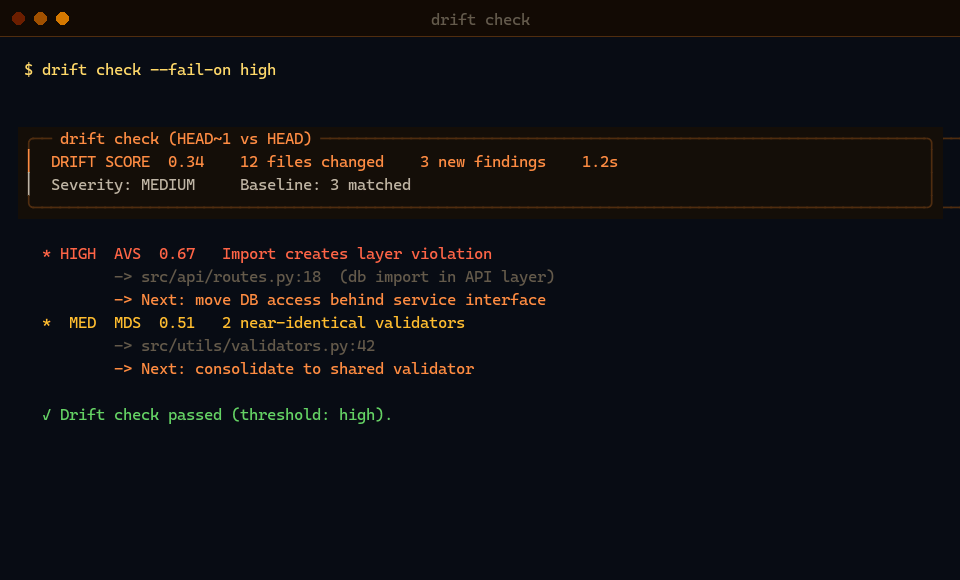
| 3–4 — Improve | Fix findings, block regressions | drift check --fail-on high (CI or pre-push) · drift trend |
Score is lower than baseline; CI gate is green |
Which profile? AI-heavy codebase →
drift init -p vibe-coding. Unsure →drift init(default). You can switch later.
Before a session — generate guardrails:
drift brief --task "refactor the auth service" --format markdown
# → paste output into your agent prompt before delegationAfter a session — enforce structure:
drift check --fail-on high # local or CI gate
drift check --fail-on none # pre-commit hook (advisory, report-only)
drift analyze --repo . --format json # full report
drift adr --repo . # list active ADRs and their relevance to scopeDrift findings use short codes. Here are the five you'll see most often:
| Code | Signal | What it catches | Example |
|---|---|---|---|
| PFS | Pattern Fragmentation | Same pattern reimplemented inconsistently across modules | 3 different parse_config() helpers |
| MDS | Mutant Duplicate | Near-duplicate functions that diverged over time | Two validate_input() with subtle differences |
| AVS | Architecture Violation | Imports that cross declared layer boundaries | api/ importing directly from db/ |
| BAT | Bypass Accumulation | Growing # noqa, type: ignore, pragma bypasses |
40 suppressions added in one sprint |
| TPD | Test Polarity Deficit | Missing negative / error-path test coverage | Only happy-path tests for auth module |
Every finding includes a human-readable reason and a concrete next_action. Full reference: all 24 signals →
| AI Tools (MCP) | Copilot Chat | CI/CD | Git Hooks | Install |
|---|---|---|---|---|
| Cursor · Claude Code · Copilot | /drift-fix-plan · /drift-export-report · /drift-auto-fix-loop |
GitHub Actions · SARIF | pre-commit · pre-push | pip · pipx · uvx · Homebrew · Docker |
Bootstrap: drift init --mcp --ci --hooks scaffolds all integrations at once. Copilot Chat: drift kit init (once per repo → /drift-fix-plan). Language support: Python (full) · TypeScript/TSX 17/24 via pip install 'drift-analyzer[typescript]' · language matrix
# Try it — add this to .github/workflows/drift.yml
name: Drift
on: [push, pull_request]
jobs:
drift:
runs-on: ubuntu-latest
permissions:
security-events: write # for SARIF upload
pull-requests: write # for PR comments
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0 # full history for temporal signals
- uses: mick-gsk/drift@v2
with:
fail-on: none # report-only — tighten once you trust the output
upload-sarif: "true" # findings appear as PR annotations
comment: "true" # summary comment on each PROutputs available for downstream steps: drift-score, grade, severity, finding-count, badge-svg
Cursor, Claude Code, and Copilot call drift directly via MCP server — the agent runs a full session loop:
| Phase | MCP Tool | What it does |
|---|---|---|
| Plan | drift_brief |
Scope-aware guardrails injected into the agent prompt |
| Code | drift_nudge |
Real-time safe_to_commit check after each edit |
| Verify | drift_diff |
Full before/after comparison before push |
| Learn | drift_feedback |
Mark findings as TP/FP — calibrates signal weights |
VS Code — add to .vscode/mcp.json:
{
"servers": {
"drift": {
"type": "stdio",
"command": "drift",
"args": ["mcp", "--serve"]
}
}
}Claude Desktop — add to claude_desktop_config.json:
{
"mcpServers": {
"drift": {
"command": "drift",
"args": ["mcp", "--serve"]
}
}
}Cursor — add to .cursor/mcp.json:
{
"mcpServers": {
"drift": {
"type": "stdio",
"command": "drift",
"args": ["mcp", "--serve"]
}
}
}Or auto-generate: pip install drift-analyzer[mcp] && drift init --mcp
pre-commit: Add drift diff --staged-only as a hook — findings block the commit before they reach CI.
# .pre-commit-config.yaml
repos:
- repo: https://github.com/mick-gsk/drift-pre-commit
rev: v1.0.0
hooks:
- id: drift-check📖 Full integration guide → · drift-pre-commit repo →
The vscode-drift extension shows findings as inline CodeLens annotations — no terminal needed.
auth/handler.py [Drift · C · score 0.71 · 3 findings (1 high, 2 medium)]
def authenticate(...): [Drift · PFS · co-change coupling to auth/service.py · high]
Install from VSIX:
pip install drift-analyzer # drift must be on PATH
code --install-extension vscode-drift-0.1.0.vsixDownload the VSIX from the Releases page, or build from source:
cd extensions/vscode-drift && npm install && npm run compileAfter drift analyze, drift writes .vscode/drift-session.json and shows a
Copilot Chat Handoff panel in the terminal. Open VS Code Copilot Chat and call:
| Slash command | What it does |
|---|---|
/drift-fix-plan |
Prioritized repair tasks from the latest findings |
/drift-export-report |
Self-contained findings report as Markdown |
/drift-auto-fix-loop |
Step through findings one-at-a-time with confirm/skip gates |
One-time setup — one command:
drift kit init # scaffolds prompt files + VS Code settings — run once per repoNo extension install needed. drift kit init creates .github/prompts/ with all three prompt files and merges chat.promptFilesLocations into .vscode/settings.json without touching your existing keys. Idempotent — safe to re-run.
📖 VS Code Copilot Chat Workflow guide →
Pick a profile that matches your project — or start with default and calibrate later:
| Profile | Best for | Command |
|---|---|---|
| default | Most projects | drift init |
| vibe-coding | AI-heavy codebases (Copilot, Cursor, Claude) | drift init -p vibe-coding |
| strict | Mature projects, zero tolerance | drift init -p strict |
| fastapi | Web APIs with router/service/DB layers | drift init -p fastapi |
| library | Reusable PyPI packages | drift init -p library |
| monorepo | Multi-package repos | drift init -p monorepo |
| quick | First exploration, demos | drift init -p quick |
Team tip: Commit drift.yaml → CI enforces the same thresholds. Inspect with drift config show --repo ..
📖 Profile gallery with full details → · Configuration reference →
Drift is most useful when you track score deltas, not snapshots.
Day 0 — capture your baseline:
drift analyze --repo . --format json > baseline.json
# note the composite score, e.g. 12.5Ongoing — ratchet the threshold down:
# drift.yaml — tighten after each successful sprint
thresholds:
fail_on: high # block high-severity findings
max_score: 10.0 # lower this as your score improvesWeekly — track the trend:
drift trend # shows score evolution over recent commitsExample outcome: "Score dropped from 12.5 → 8.3 in 4 weeks — 3 PFS and 1 AVS finding resolved, CI gate tightened from 12.0 to 9.0." The GitHub Action exposes drift-score as a step output — pipe it to a dashboard or Slack webhook.
Advanced: Adaptive learning, Negative context library, Guided mode
Drift does not treat all signals equally forever. It maintains a per-repo profile:
- Adaptive calibration engine uses precision-weighted linear interpolation across three evidence sources: explicit
drift feedback mark, git outcome correlation, and GitHub issue/PR label correlation. As feedback accumulates, observed signal precision gradually overrides default weights (see calibration design). - Feedback events are stored as structured
FeedbackEventrecords and can be reloaded and replayed across versions (record_feedback,load_feedback). - Profile builder (
build_profile) produces a calibrated weight profile thatdrift checkanddrift briefuse to focus on the most trusted signals in your codebase.
CLI surface: drift feedback, drift calibrate, drift precision (for your own ground-truth checks).
Drift can turn findings into a structured "what NOT to do" library for coding agents:
- Per-signal generators map each signal (PFS, MDS, AVS, BEM, TPD, …) to one or more
NegativeContextitems with category, scope, rationale, and confidence. - Anti-pattern IDs like
neg-MDS-…are deterministic and stable — ideal for referencing in policies and prompts. - Forbidden vs. canonical patterns: each item includes a concrete anti-pattern code block and a canonical alternative, often tagged with CWE and FMEA RPN.
- Security-aware: mappings for
MISSING_AUTHORIZATION,HARDCODED_SECRET, andINSECURE_DEFAULTgenerate explicit security guardrails for agents.
API: findings_to_negative_context() and negative_context_to_dict() deliver agent-consumable JSON for drift_nudge, drift brief, and other tools.
If your team ships most changes via AI coding tools (Copilot, Cursor, Claude), drift includes a guided mode:
- CLI guide:
drift startprints the three-command journey for new users:analyze → fix-plan → checkwith safe defaults. - Vibe-coding playbook: examples/vibe-coding/README.md documents a 30-day rollout plan (IDE → commit → PR → merge → trend) with concrete scripts and metrics.
- Problem-to-signal map: maps typical vibe-coding issues (duplicate helpers, boundary erosion, happy-path-only tests, type-ignore buildup) directly to signals like MDS, PFS, AVS, TPD, BAT, CIR, CCC.
- Baseline + ratchet: ready-made
drift.yaml, CI gate, pre-push hook and weekly scripts implement a ratcheting quality gate over time.
📖 Start here if you are a heavy AI-coding user: Vibe-coding technical debt solution →
From Ruff / pylint: Drift operates one layer above single-file style. It detects when AI generates the same error handler four different ways across modules — something no linter sees.
From Semgrep / CodeQL: Semgrep finds known vulnerability patterns in single files. Drift finds structural erosion across files — pattern fragmentation, layer violations, temporal volatility — that security scanners don't target. Semgrep Pro Engine adds cross-file dataflow analysis for security — drift adds cross-file structural coherence analysis for architecture. Different questions.
From SonarQube: Drift runs locally with zero server setup and produces deterministic, reproducible findings per signal. Add it alongside SonarQube — not instead. See drift vs SonarQube for the detailed comparison.
From GitHub Copilot Code Review: Copilot Review checks the PR after the code is written. Drift operates before (drift brief generates guardrails before an agent task starts) and during (drift nudge gives directional feedback inside the editing session). Use both — different positions in the workflow.
From jscpd / CPD: Drift's duplicate detection is AST-level, not text-level. It finds near-duplicates that text diff misses and places them in architectural context.
| Capability | drift | SonarQube | Ruff / pylint / mypy | Semgrep / CodeQL | jscpd / CPD |
|---|---|---|---|---|---|
| Pattern Fragmentation across modules | ✔ | — | — | — | — |
| Near-Duplicate Detection (AST-level) | ✔ | Partial (text) | — | — | ✔ (text) |
| Architecture Violation signals | ✔ | Partial | — | Partial (custom rules) | — |
| Temporal / change-history signals | ✔ | — | — | — | — |
| GitHub Code Scanning via SARIF | ✔ | ✔ | — | ✔ | — |
| Adaptive per-repo calibration | ✔ | — | — | — | — |
| MCP server for AI agents | ✔ | — | — | — | — |
| Zero server setup | ✔ | — | ✔ | ✔ | ✔ |
| TypeScript support | Partial ¹ | ✔ | — | ✔ | ✔ |
✔ = within primary design scope · — = not a primary design target · Partial = limited coverage
¹ Via drift-analyzer[typescript]. 17/24 signals supported via tree-sitter. Python is the primary analysis target.
Comparison reflects primary design scope per STUDY.md §9. This table was authored by the maintainer and has not been independently verified. Corrections welcome via discussion.
Show your repo's drift score with a shields.io badge:
drift badge # prints URL + Markdown snippet
drift badge --format svg -o badge.svg # self-contained SVGPaste the Markdown output into your README:
[](https://github.com/mick-gsk/drift)Automate in CI: The GitHub Action exposes a badge-svg output — pipe it into your repo or a dashboard.
| Topic | Description |
|---|---|
| Quick Start | Install → first findings in 2 minutes |
| Brief & Guardrails | Pre-task agent workflow |
| CI Integration | GitHub Action, SARIF, pre-commit, progressive rollout |
| Signal Reference | All 25 signals with detection logic |
| Benchmarking & Trust | Precision/Recall, methodology, artifacts |
| MCP & AI Tools | Cursor, Claude Code, Copilot, HTTP API |
| Configuration | drift.yaml, layer boundaries, signal weights |
| Configuration Levels | Zero-Config → Preset → YAML → Calibration → MCP → CI |
| Calibration & Feedback | Adaptive signal reweighting, feedback workflow |
ADR Inspection (drift adr) |
List active ADRs from docs/decisions/ — filter by task or scope |
| Vibe-coding Playbook | 30-day rollout guide for AI-heavy teams |
| Open Research Questions | 5 falsifiable hypotheses on validity and effectiveness |
| Contributing | Dev setup, FP/FN reporting, signal development |
No Python files found
drift walks the repo starting from the path passed to --repo. If the path is wrong or the repo uses a non-standard layout, use --repo /absolute/path/to/project and verify via drift analyze --repo . --format json | python -m json.tool | Select-String files.
Shallow clone — git signals are missing or unreliable
Time-based and co-change signals (TVS, CCC, AVS) require full git history. Unshallow the clone:
git fetch --unshallowIn CI (GitHub Actions), add fetch-depth: 0 to your actions/checkout step.
drift.yaml schema validation failed
Validate your config against the schema:
python -m jsonschema -i drift.yaml drift.schema.json # requires pip install jsonschemaOr regenerate a fresh config: drift init (overwrites drift.yaml with safe defaults).
drift: command not found after install
The drift binary may not be on your PATH. Check:
which drift # macOS/Linux
where drift # Windows
python -m drift analyze --repo . # always works regardless of PATHIf you installed with pip install --user, add ~/.local/bin (Linux/macOS) or %APPDATA%\Python\Scripts (Windows) to your PATH.
Drift's biggest blind spots are found by people running it on codebases the maintainers have never seen. A well-documented false positive can be more valuable than a new feature.
| I want to… | Go here |
|---|---|
| Ask a usage question | Discussions |
| Report a false positive / false negative | FP/FN template |
| Report a bug | Bug report |
| Suggest a feature | Feature request |
| Propose a contribution before coding | Contribution proposal |
| Report a security vulnerability | SECURITY.md — not a public issue |
git clone https://github.com/mick-gsk/drift.git && cd drift && make install
make test-fastSee CONTRIBUTING.md · ROADMAP.md
Drift's pipeline is deterministic and benchmark artifacts are published in the repository — claims can be inspected, not just trusted.
| Metric | Value | Artifact |
|---|---|---|
| Wild-repo precision | 77 % strict / 95 % lenient (5 repos) | study §5 |
| Ground-truth regression | 0 FP, 0 FN (84 TP, 206 fixtures) | v2.7.0 baseline |
| Mutation recall | 75 % (75/100 injected) | mutation benchmark |
| Agent session score delta | 0.495→0.506 (1 live run) ² | Copilot Autopilot artefacts |
² Single uncontrolled run — see RESEARCH.md H4/H5 for what a controlled study would require.
- No LLM in detection. The deterministic core uses no LLM inference — same input, same output. Optional local embeddings (
pip install drift-analyzer[embeddings]) improve near-duplicate detection but are not required and do not call external services. - Single-rater caveat: ground-truth classification is not yet independently replicated.
- Small-repo noise: repositories with few files can produce noisy scores. Calibration mitigates but does not eliminate this.
- Temporal signals depend on clone depth and git history quality.
- The composite score is orientation, not a verdict. Interpret deltas via
drift trend, not isolated snapshots. - Own score context (0.36): Drift's self-score is driven primarily by architecture violations and explainability deficit (undocumented internal functions). Pattern fragmentation in modules with intentionally diverse error-handling contracts (signals, API, calibration, integrations) is suppressed via
path_overrides— those variations are architectural, not accidental. The score reflects a fast-moving codebase that prioritises signal correctness over internal documentation. See drift_self.json for the full breakdown. - Signal overlap: Some signals measure related phenomena (e.g., MDS and PFS both detect code similarity; CCC and TVS both use git history). A formal inter-signal correlation analysis has not been conducted. Overlap does not produce double-counting in the composite score (each signal contributes independently), but it means some findings may describe the same underlying issue from different angles.
- Weight derivation: Default signal weights for the 6 original signals were derived via rank-correlation (Kendall's τ) against manual architectural assessments on 5 open-source repos (single rater). Weights for the 18 newer signals are conservative heuristic assignments pending broader validation. Full methodology: STUDY.md §1, ADR-003.
Full methodology: Benchmarking & Trust · Full Study · Open Research Questions
Drift detects architectural erosion: structural patterns that accumulate silently across many commits and that static analysis, linters, and type checkers cannot see because they only look at individual files in isolation.
Drift is NOT a replacement for:
| Tool | What it does | Why drift doesn't replace it |
|---|---|---|
| ruff / flake8 / pylint | Style, syntax, import order, per-file lint rules | Drift does not enforce code style. Run your linter as-is. |
| mypy / pyright | Type correctness | Drift does not check types. |
| Semgrep / Bandit | Security vulnerability patterns, taint analysis | Drift does not scan for CVEs or injection vectors. |
| SonarQube / SonarLint | Code quality metrics, duplication, test coverage gaps | Drift measures cross-file structural coherence, not coverage or per-function quality. |
| pytest / coverage.py | Test execution and coverage measurement | Drift does not run tests. |
What drift adds on top of those tools: It detects whether the structure of your codebase is drifting away from its intended architecture — specifically the patterns that emerge from AI-assisted development (Cursor, Copilot, Claude) when no human has reviewed the cumulative effect of 50+ small PRs.
Primary target: teams and solo developers using AI coding tools (Cursor, GitHub Copilot, Claude Code) where agent-generated code accumulates faster than architectural review can keep up.
Drift is maintained by Mick Gottschalk as an independent open-source project.
- License: MIT — fork-safe, vendor-lock-free, reproducible CI.
- Bus factor mitigation: All signals, benchmarks, and release automation are fully documented and reproducible without the maintainer. The project has zero external service dependencies for core analysis.
- Funding: Currently unfunded. If your team relies on drift, consider sponsoring to support continued development.
- Response target: First reply within 72 hours on issues and discussions.
MIT. See LICENSE.